Publications
Publications at top AI / ML venues (e.g. NeurIPS, CVPR, ICML, ICLR) typically have 20-25 % acceptance rates.
2024
-
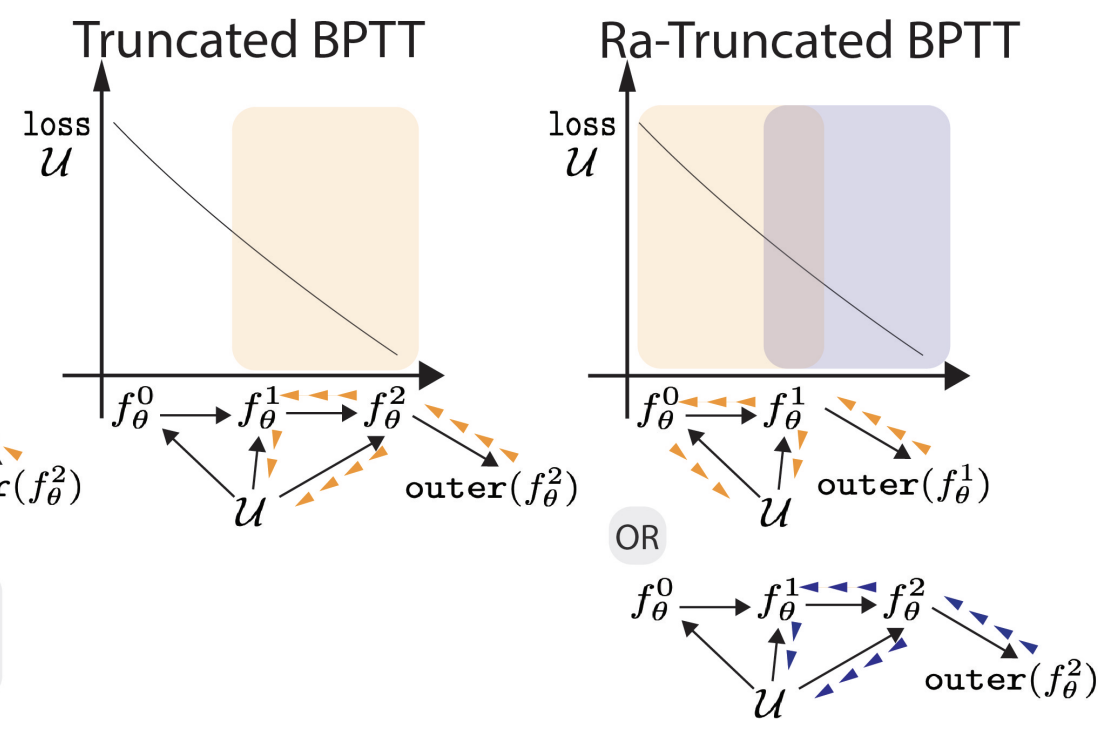 Embarrassingly Simple Dataset DistillationYunzhen Feng, Shanmukha Ramakrishna Vedantam, and Julia KempeICLR, Oct 2024
Embarrassingly Simple Dataset DistillationYunzhen Feng, Shanmukha Ramakrishna Vedantam, and Julia KempeICLR, Oct 2024Dataset distillation extracts a small set of synthetic training samples from a large dataset with the goal of achieving competitive performance on test data when trained on this sample. In this work, we tackle dataset distillation at its core by treating it directly as a bilevel optimization problem. Re-examining the foundational back-propagation through time method, we study the pronounced variance in the gradients, computational burden, and long-term dependencies. We introduce an improved method: Random Truncated Backpropagation Through Time (RaT-BPTT) to address them. RaT-BPTT incorporates a truncation coupled with a random window, effectively stabilizing the gradients and speeding up the optimization while covering long dependencies. This allows us to establish new state-of-the-art for a variety of standard dataset benchmarks. A deeper dive into the nature of distilled data unveils pronounced intercorrelation. In particular, subsets of distilled datasets tend to exhibit much worse performance than directly distilled smaller datasets of the same size. Leveraging RaT-BPTT, we devise a boosting mechanism that generates distilled datasets that contain subsets with near optimal performance across different data budgets.

2023
-
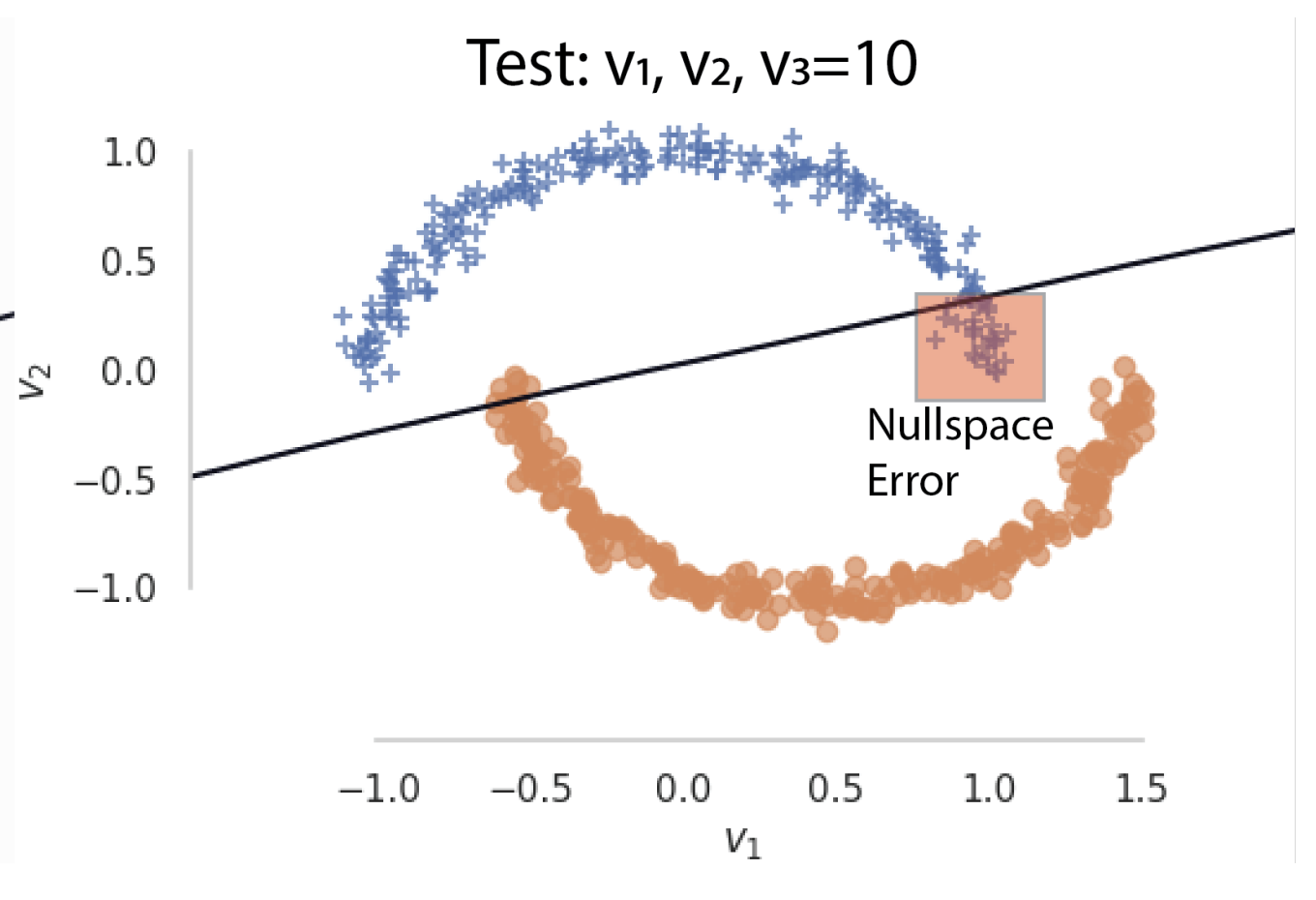 Don’t forget the nullspace! Nullspace occupancy as a mechanism for out of distribution failureDaksh Idnani, Vivek Madan, Naman Goyal, and 2 more authorsIn ICLR, Sep 2023
Don’t forget the nullspace! Nullspace occupancy as a mechanism for out of distribution failureDaksh Idnani, Vivek Madan, Naman Goyal, and 2 more authorsIn ICLR, Sep 2023Out of distribution (OoD) generalization has received considerable interest in recent years. In this work, we identify a particular failure mode of OoD generalization for discriminative classifiers that is based on test data (from a new domain) lying in the nullspace of features learnt from source data. We demonstrate the existence of this failure mode across multiple networks trained across RotatedMNIST, PACS, TerraIncognita, DomainNet and ImageNet-R datasets. We then study different choices for characterizing the feature space and show that projecting intermediate representations onto the span of directions that obtain maximum training accuracy provides consistent improvements in OoD performance. Finally, we show that such nullspace behavior also provides an insight into neural networks trained on poisoned data. We hope our work galvanizes interest in the relationship between the nullspace occupancy failure mode and generalization.
-
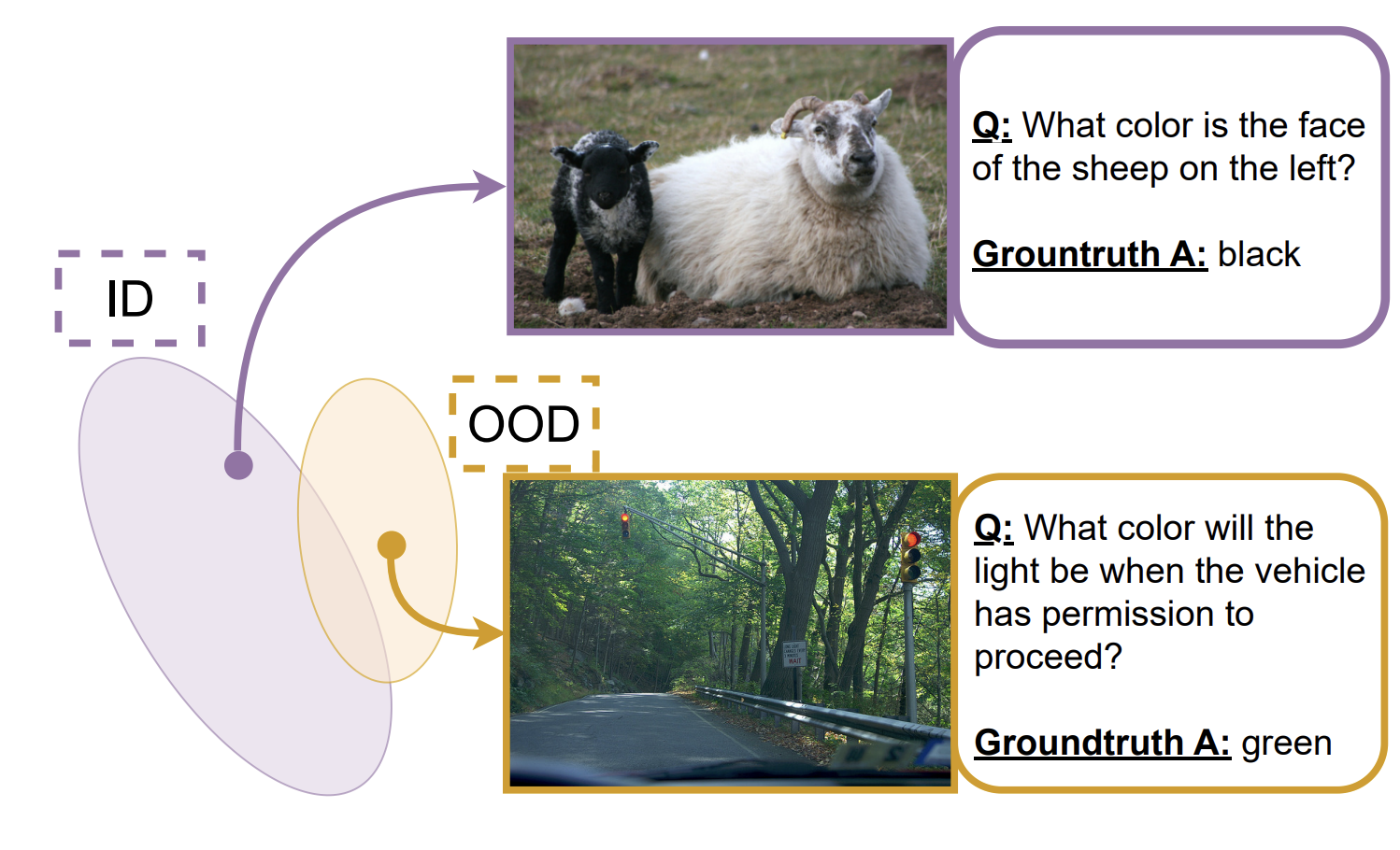 Improving selective visual question answering by learning from your peersCorentin Dancette, Spencer Whitehead, Rishabh Maheshwary, and 5 more authorsIn CVPR, Jun 2023
Improving selective visual question answering by learning from your peersCorentin Dancette, Spencer Whitehead, Rishabh Maheshwary, and 5 more authorsIn CVPR, Jun 2023Despite advances in Visual Question Answering (VQA), the ability of models to assess their own correctness remains underexplored. Recent work has shown that VQA models, out-of-the-box, can have difficulties abstaining from answering when they are wrong. The option to abstain, also called Selective Prediction, is highly relevant when deploying systems to users who must trust the system’s output (e.g., VQA assistants for users with visual impairments). For such scenarios, abstention can be especially important as users may provide out-of-distribution (OOD) or adversarial inputs that make incorrect answers more likely. In this work, we explore Selective VQA in both in-distribution (ID) and OOD scenarios, where models are presented with mixtures of ID and OOD data. The goal is to maximize the number of questions answered while minimizing the risk of error on those questions. We propose a simple yet effective Learning from Your Peers (LYP) approach for training multimodal selection functions for making abstention decisions. Our approach uses predictions from models trained on distinct subsets of the training data as targets for optimizing a Selective VQA model. It does not require additional manual labels or held-out data and provides a signal for identifying examples that are easy/difficult to generalize to. In our extensive evaluations, we show this benefits a number of models across different architectures and scales. Overall, for ID, we reach 32.92% in the selective prediction metric coverage at 1% risk of error (C@1%) which doubles the previous best coverage of 15.79% on this task. For mixed ID/OOD, using models’ softmax confidences for abstention decisions performs very poorly, answering <5% of questions at 1% risk of error even when faced with only 10% OOD examples, but a learned selection function with LYP can increase that to 25.38% C@1%.
-
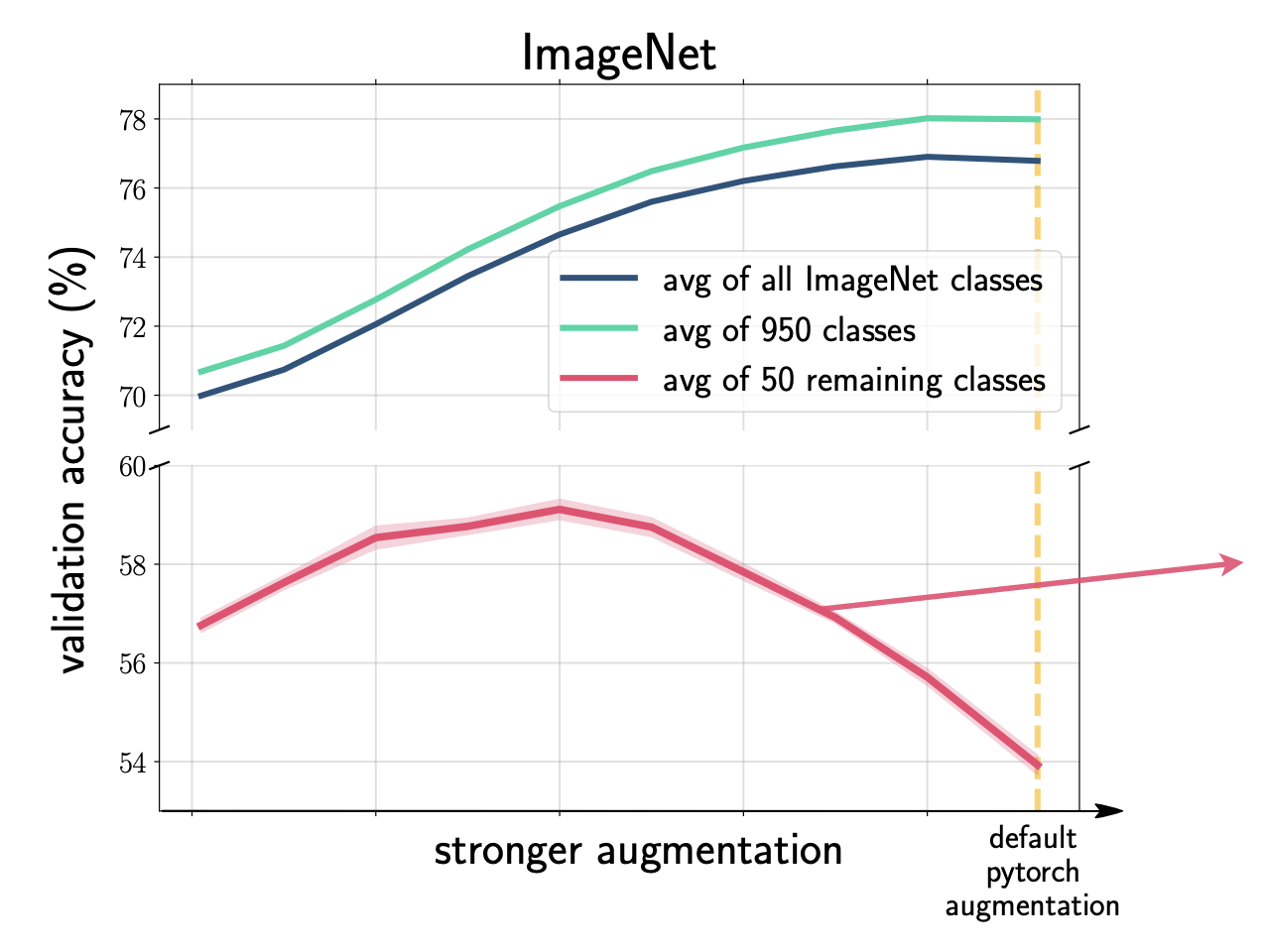 Understanding the detrimental class-level effects of data augmentationPolina Kirichenko, Mark Ibrahim, Randall Balestriero, and 4 more authorsIn NeurIPS, Dec 2023
Understanding the detrimental class-level effects of data augmentationPolina Kirichenko, Mark Ibrahim, Randall Balestriero, and 4 more authorsIn NeurIPS, Dec 2023Data augmentation (DA) encodes invariance and provides implicit regularization critical to a model’s performance in image classification tasks. However, while DA improves average accuracy, recent studies have shown that its impact can be highly class dependent: achieving optimal average accuracy comes at the cost of significantly hurting individual class accuracy by as much as 20% on ImageNet. There has been little progress in resolving class-level accuracy drops due to a limited understanding of these effects. In this work, we present a framework for understanding how DA interacts with class-level learning dynamics. Using higher-quality multi-label annotations on ImageNet, we systematically categorize the affected classes and find that the majority are inherently ambiguous, co-occur, or involve fine-grained distinctions, while DA controls the model’s bias towards one of the closely related classes. While many of the previously reported performance drops are explained by multi-label annotations, our analysis of class confusions reveals other sources of accuracy degradation. We show that simple class-conditional augmentation strategies informed by our framework improve performance on the negatively affected classes.
-
 Hyperbolic Image-Text RepresentationsKaran Desai, Maximilian Nickel, Tanmay Rajpurohit, and 2 more authorsIn ICML, Apr 2023
Hyperbolic Image-Text RepresentationsKaran Desai, Maximilian Nickel, Tanmay Rajpurohit, and 2 more authorsIn ICML, Apr 2023Visual and linguistic concepts naturally organize themselves in a hierarchy, where a textual concept “dog” entails all images that contain dogs. Despite being intuitive, current large-scale vision and language models such as CLIP do not explicitly capture such hierarchy. We propose MERU, a contrastive model that yields hyperbolic representations of images and text. Hyperbolic spaces have suitable geometric properties to embed tree-like data, so MERU can better capture the underlying hierarchy in image-text datasets. Our results show that MERU learns a highly interpretable and structured representation space while being competitive with CLIP’s performance on standard multi-modal tasks like image classification and image-text retrieval. Our code and models are available at https://www.github.com/facebookresearch/meru




2022
-
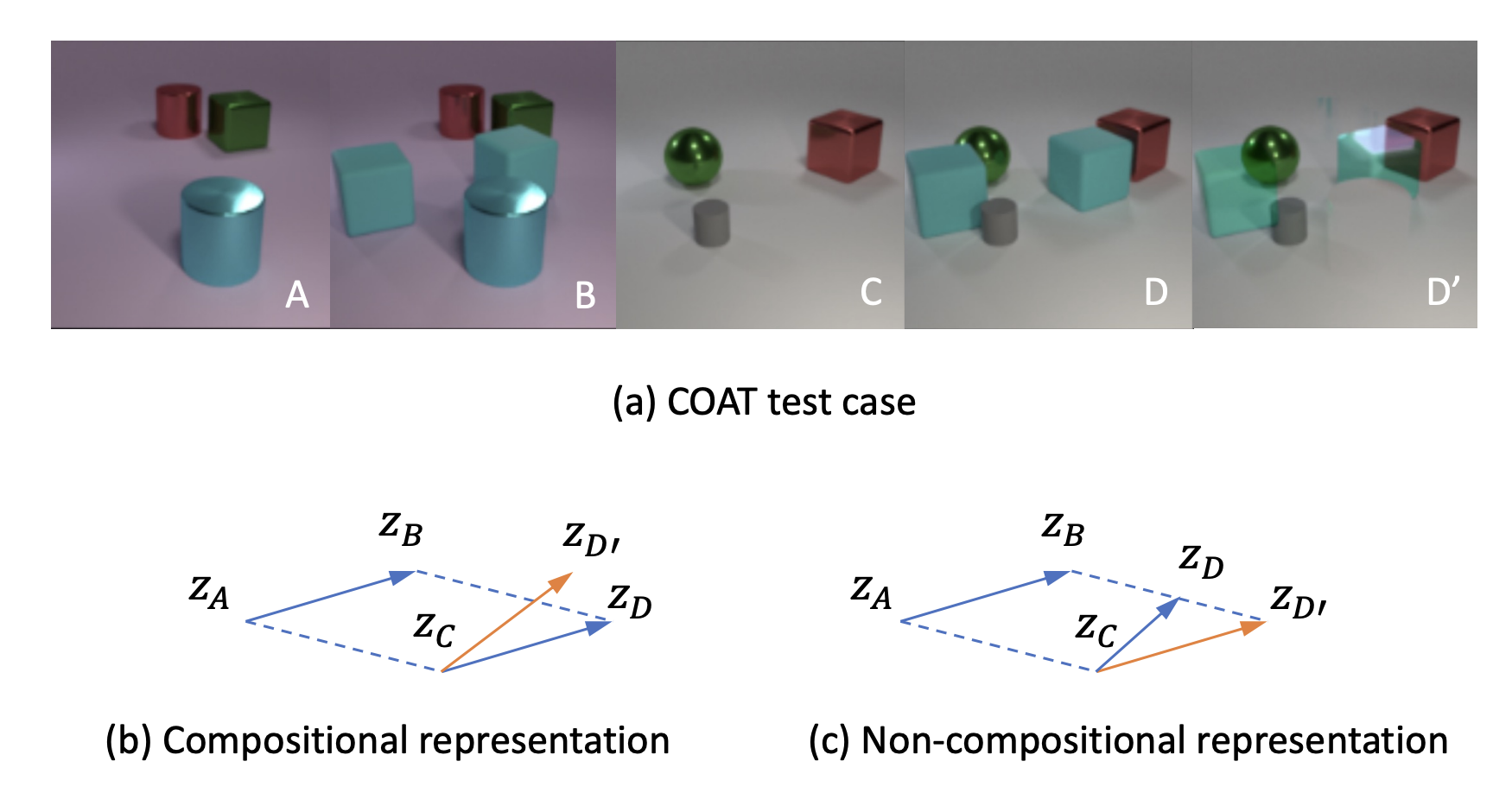 COAT: Measuring object compositionality in emergent representationsSirui Xie, Ari S Morcos, Song-Chun Zhu, and 1 more authorICML, Apr 2022
COAT: Measuring object compositionality in emergent representationsSirui Xie, Ari S Morcos, Song-Chun Zhu, and 1 more authorICML, Apr 2022Learning representations that can decompose a multi-object scene into its constituent objects and recompose them flexibly is desirable for object-oriented reasoning and planning. Built upon object masks in the pixel space, existing metrics for objectness can only evaluate generative models with an object-specific “slot” structure. We propose to directly measure compositionality in the representation space as a form of objectness, making such evaluations tractable for a wider class of models. Our metric, COAT (Compositional Object Algebra Test), evaluates if a generic representation exhibits certain geometric properties that underpin object compositionality beyond what is already captured by the raw pixel space. Our experiments on the popular CLEVR (Johnson et.al., 2018) domain reveal that existing disentanglement-based generative models are not as compositional as one might expect, suggesting room for further modeling improvements. We hope our work allows for a unified evaluation of object-centric representations, spanning generative as well as discriminative, self-supervised models.

2021
-
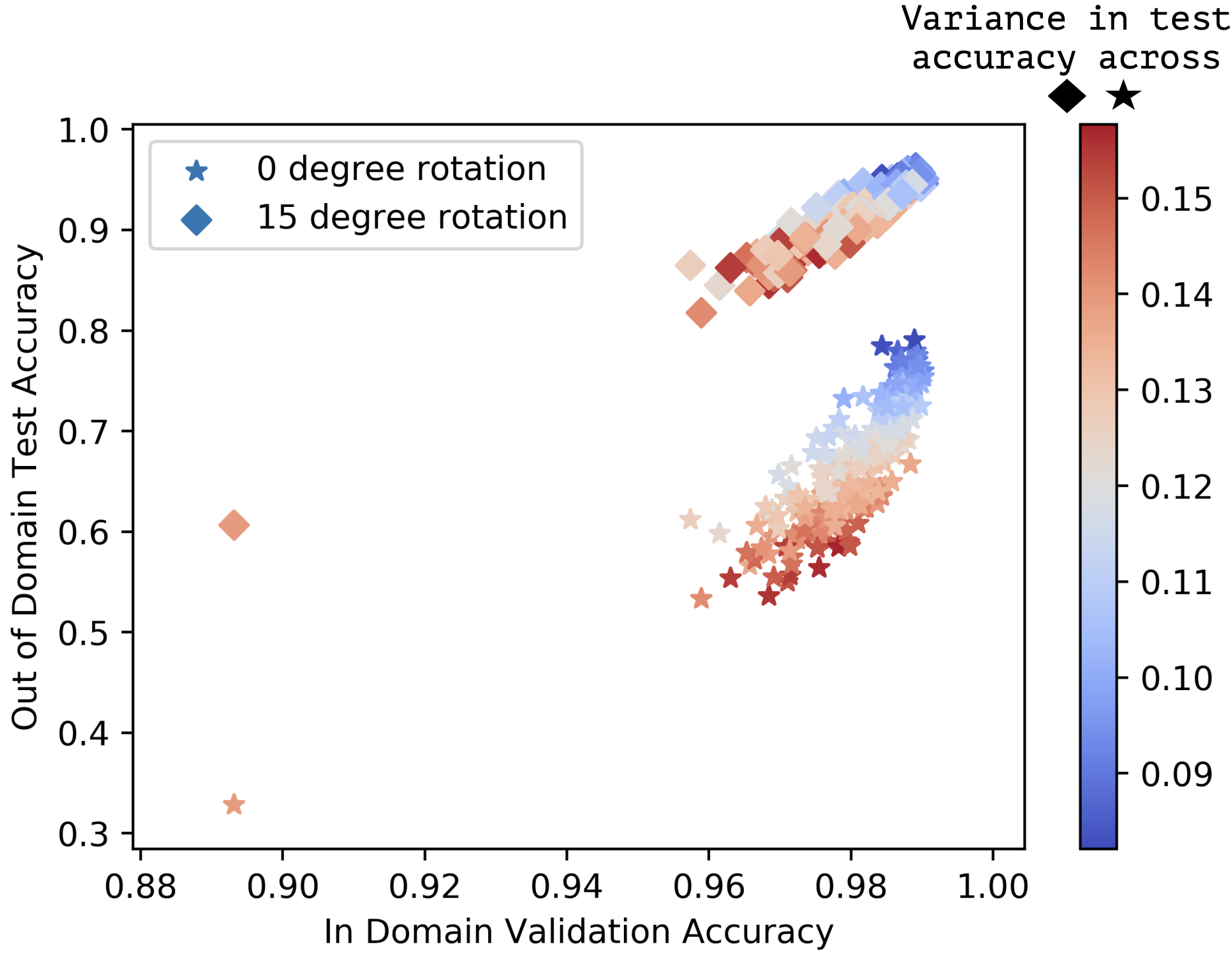 An empirical investigation of domain generalization with empirical risk minimizersRamakrishna VedantamNeurIPS, Dec 2021
An empirical investigation of domain generalization with empirical risk minimizersRamakrishna VedantamNeurIPS, Dec 2021Recent work demonstrates that deep neural networks trained using Empirical Risk Minimization (ERM) can generalize under distribution shift, outperforming specialized training algorithms for domain generalization. The goal of this paper is to further understand this phenomenon. In particular, we study the extent to which the seminal domain adaptation theory of Ben-David et al. (2007) explains the performance of ERMs. Perhaps surprisingly, we find that this theory does not provide a tight explanation of the out-of-domain generalization observed across a large number of ERM models trained on three popular domain generalization datasets. This motivates us to investigate other possible measures-that, however, lack theory-which could explain generalization in this setting. Our investigation reveals that measures relating to the Fisher information, predictive entropy, and maximum mean discrepancy are good predictors of the out-of-distribution generalization of ERM models. We hope that our work helps galvanize the community towards building a better understanding of when deep networks trained with ERM generalize out-of-distribution.
-
 CURI: A Benchmark for Productive Concept Learning Under UncertaintyRamakrishna Vedantam, Arthur Szlam, Maximilian Nickel, and 2 more authorsIn ICML, Dec 2021
CURI: A Benchmark for Productive Concept Learning Under UncertaintyRamakrishna Vedantam, Arthur Szlam, Maximilian Nickel, and 2 more authorsIn ICML, Dec 2021Humans can learn and reason under substantial uncertainty in a space of infinitely many concepts, including structured relational concepts (“a scene with objects that have the same color”) and ad-hoc categories defined through goals (“objects that could fall on one’s head”). In contrast, standard classification benchmarks: 1) consider only a fixed set of category labels, 2) do not evaluate compositional concept learning and 3) do not explicitly capture a notion of reasoning under uncertainty. We introduce a new few-shot, meta-learning benchmark, Compositional Reasoning Under Uncertainty (CURI) to bridge this gap. CURI evaluates different aspects of productive and systematic generalization, including abstract understandings of disentangling, productive generalization, learning boolean operations, variable binding, etc. Importantly, it also defines a model-independent “compositionality gap” to evaluate the difficulty of generalizing out-of-distribution along each of these axes. Extensive evaluations across a range of modeling choices spanning different modalities (image, schemas, and sounds), splits, privileged auxiliary concept information, and choices of negatives reveal substantial scope for modeling advances on the proposed task. All code and datasets will be available online.


2020
-
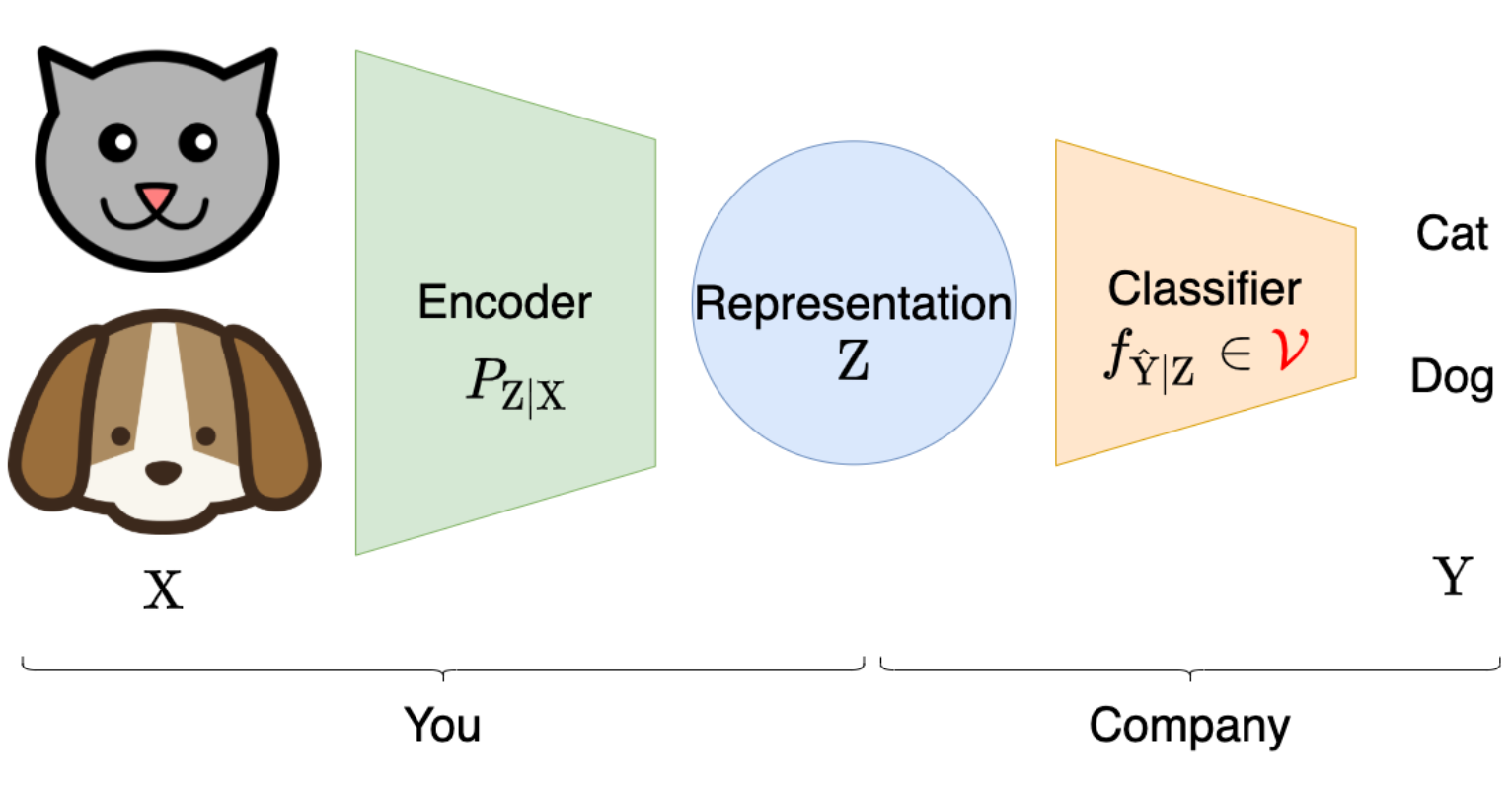 Learning Optimal Representations with the Decodable Information BottleneckYann Dubois, Douwe Kiela, David J Schwab, and 1 more authorIn NeurIPS, Sep 2020
Learning Optimal Representations with the Decodable Information BottleneckYann Dubois, Douwe Kiela, David J Schwab, and 1 more authorIn NeurIPS, Sep 2020We address the question of characterizing and finding optimal representations for supervised learning. Traditionally, this question has been tackled using the Information Bottleneck, which compresses the inputs while retaining information about the targets, in a decoder-agnostic fashion. In machine learning, however, our goal is not compression but rather generalization, which is intimately linked to the predictive family or decoder of interest (e.g. linear classifier). We propose the Decodable Information Bottleneck (DIB) that considers information retention and compression from the perspective of the desired predictive family. As a result, DIB gives rise to representations that are optimal in terms of expected test performance and can be estimated with guarantees. Empirically, we show that the framework can be used to enforce a small generalization gap on downstream classifiers and to predict the generalization ability of neural networks.

2019
-
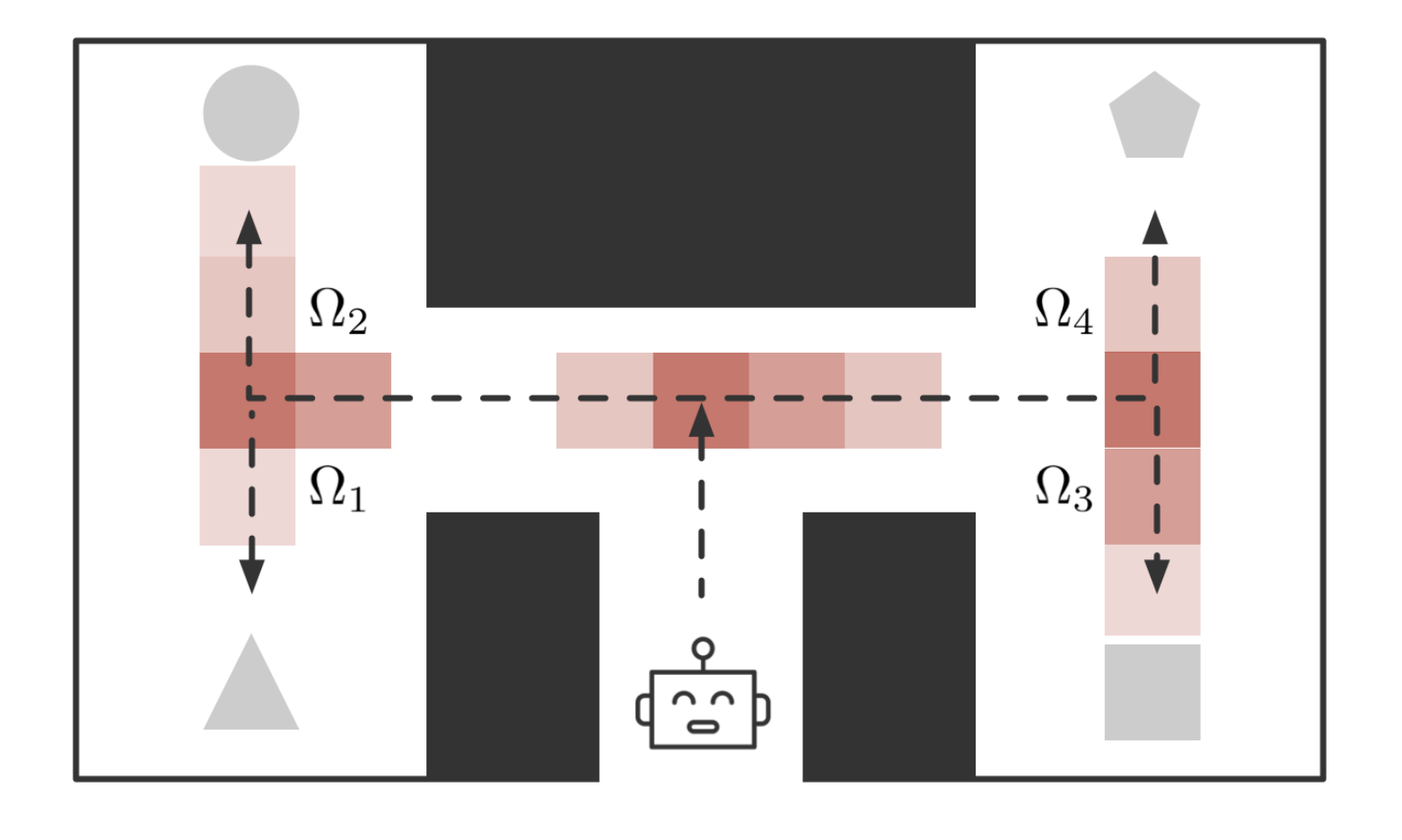 IR-VIC: Unsupervised discovery of sub-goals for transfer in RLNirbhay Modhe, Prithvijit Chattopadhyay, Mohit Sharma, and 4 more authorsIn IJCAI, Jul 2019
IR-VIC: Unsupervised discovery of sub-goals for transfer in RLNirbhay Modhe, Prithvijit Chattopadhyay, Mohit Sharma, and 4 more authorsIn IJCAI, Jul 2019We propose a novel framework to identify sub-goals useful for exploration in sequential decision making tasks under partial observability. We utilize the variational intrinsic control framework (Gregor et.al., 2016) which maximizes empowerment – the ability to reliably reach a diverse set of states and show how to identify sub-goals as states with high necessary option information through an information theoretic regularizer. Despite being discovered without explicit goal supervision, our sub-goals provide better exploration and sample complexity on challenging grid-world navigation tasks compared to supervised counterparts in prior work.
-
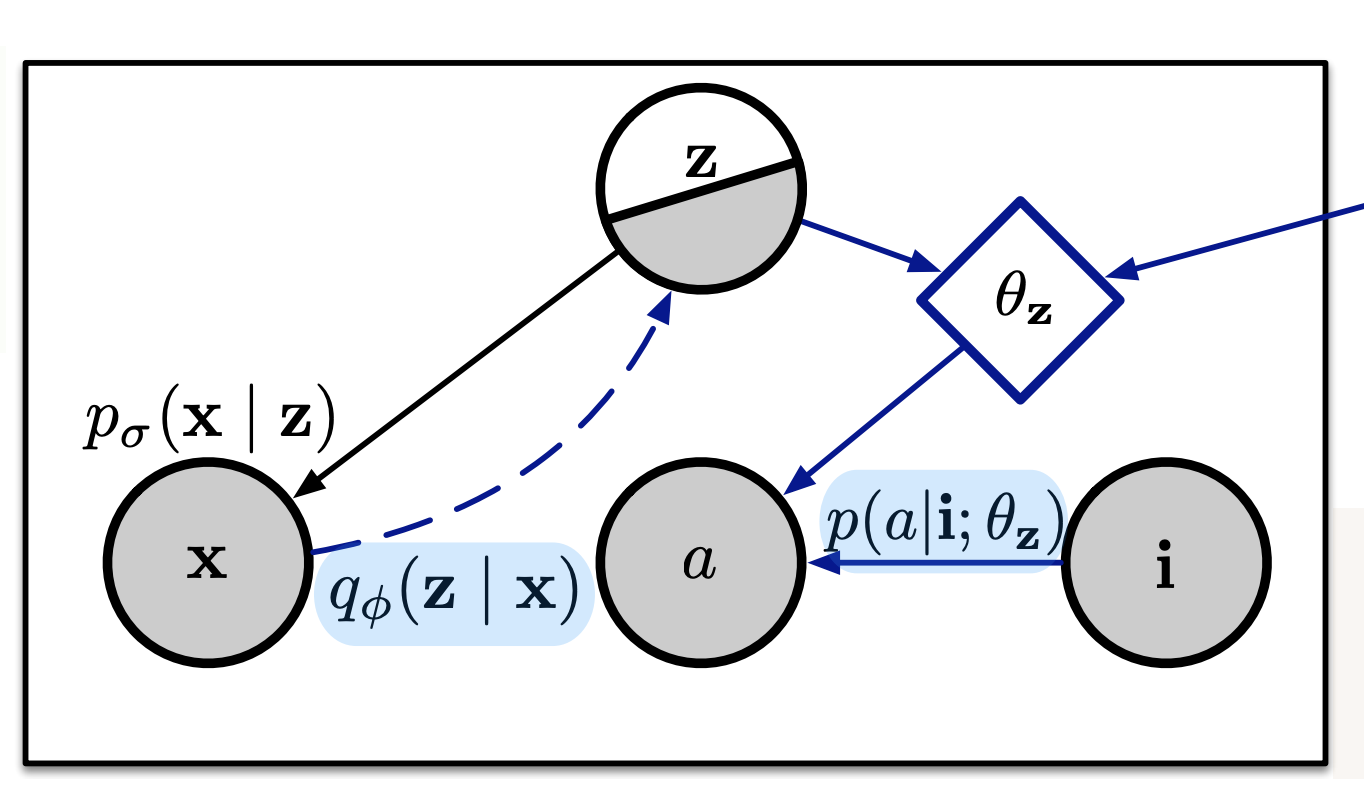 Probabilistic Neural Symbolic Models for Interpretable Visual Question AnsweringRamakrishna Vedantam, Karan Desai, Stefan Lee, and 3 more authorsIn ICML, May 2019
Probabilistic Neural Symbolic Models for Interpretable Visual Question AnsweringRamakrishna Vedantam, Karan Desai, Stefan Lee, and 3 more authorsIn ICML, May 2019We propose a new class of probabilistic neural-symbolic models, that have symbolic functional programs as a latent, stochastic variable. Instantiated in the context of visual question answering, our probabilistic formulation offers two key conceptual advantages over prior neural-symbolic models for VQA. Firstly, the programs generated by our model are more understandable while requiring lesser number of teaching examples. Secondly, we show that one can pose counterfactual scenarios to the model, to probe its beliefs on the programs that could lead to a specified answer given an image. Our results on the CLEVR and SHAPES datasets verify our hypotheses, showing that the model gets better program (and answer) prediction accuracy even in the low data regime, and allows one to probe the coherence and consistency of reasoning performed.


2018
-
 Generative Models of Visually Grounded ImaginationRamakrishna Vedantam, Ian Fischer, Jonathan Huang, and 1 more authorIn International Conference on Learning Representations (ICLR), May 2018
Generative Models of Visually Grounded ImaginationRamakrishna Vedantam, Ian Fischer, Jonathan Huang, and 1 more authorIn International Conference on Learning Representations (ICLR), May 2018It is easy for people to imagine what a man with pink hair looks like, even if they have never seen such a person before. We call the ability to create images of novel semantic concepts visually grounded imagination. In this paper, we show how we can modify variational auto-encoders to perform this task. Our method uses a novel training objective, and a novel product-of-experts inference network, which can handle partially specified (abstract) concepts in a principled and efficient way. We also propose a set of easy-to-compute evaluation metrics that capture our intuitive notions of what it means to have good visual imagination, namely correctness, coverage, and compositionality (the 3 C’s). Finally, we perform a detailed comparison of our method with two existing joint image-attribute VAE methods (the JMVAE method of Suzuki et.al. and the BiVCCA method of Wang et.al.) by applying them to two datasets: the MNIST-with-attributes dataset (which we introduce here), and the CelebA dataset.

2017
-
 Context-aware captions from context-agnostic supervisionR Vedantam, S Bengio, K Murphy, and 2 more authorsIn CVPR, May 2017
Context-aware captions from context-agnostic supervisionR Vedantam, S Bengio, K Murphy, and 2 more authorsIn CVPR, May 2017We introduce an inference technique to produce discriminative context-aware image captions (captions that describe differences between images or visual concepts) using only generic context-agnostic training data (captions that describe a concept or an image in isolation). For example, given images and captions of “siamese cat” and “tiger cat”, we generate language that describes the “siamese cat” in a way that distinguishes it from “tiger cat”. Our key novelty is that we show how to do joint inference over a language model that is context-agnostic and a listener which distinguishes closely-related concepts. We first apply our technique to a justification task, namely to describe why an image contains a particular fine-grained category as opposed to another closely-related category of the CUB-200-2011 dataset. We then study discriminative image captioning to generate language that uniquely refers to one of two semantically-similar images in the COCO dataset. Evaluations with discriminative ground truth for justification and human studies for discriminative image captioning reveal that our approach outperforms baseline generative and speaker-listener approaches for discrimination.
-
 Grad-CAM: Visual explanations from deep networks via gradient-based localizationRamprasaath R Selvaraju, Michael Cogswell, Abhishek Das, and 3 more authorsIn 2017 IEEE International Conference on Computer Vision (ICCV), Oct 2017
Grad-CAM: Visual explanations from deep networks via gradient-based localizationRamprasaath R Selvaraju, Michael Cogswell, Abhishek Das, and 3 more authorsIn 2017 IEEE International Conference on Computer Vision (ICCV), Oct 2017We propose a technique for producing “visual explanations” for decisions from a large class of CNN-based models, making them more transparent. Our approach - Gradient-weighted Class Activation Mapping (Grad-CAM), uses the gradients of any target concept, flowing into the final convolutional layer to produce a coarse localization map highlighting important regions in the image for predicting the concept. Grad-CAM is applicable to a wide variety of CNN model-families: (1) CNNs with fully-connected layers, (2) CNNs used for structured outputs, (3) CNNs used in tasks with multimodal inputs or reinforcement learning, without any architectural changes or re-training. We combine Grad-CAM with fine-grained visualizations to create a high-resolution class-discriminative visualization and apply it to off-the-shelf image classification, captioning, and visual question answering (VQA) models, including ResNet-based architectures. In the context of image classification models, our visualizations (a) lend insights into their failure modes, (b) are robust to adversarial images, (c) outperform previous methods on localization, (d) are more faithful to the underlying model and (e) help achieve generalization by identifying dataset bias. For captioning and VQA, we show that even non-attention based models can localize inputs. We devise a way to identify important neurons through Grad-CAM and combine it with neuron names to provide textual explanations for model decisions. Finally, we design and conduct human studies to measure if Grad-CAM helps users establish appropriate trust in predictions from models and show that Grad-CAM helps untrained users successfully discern a ’stronger’ nodel from a ’weaker’ one even when both make identical predictions.
-
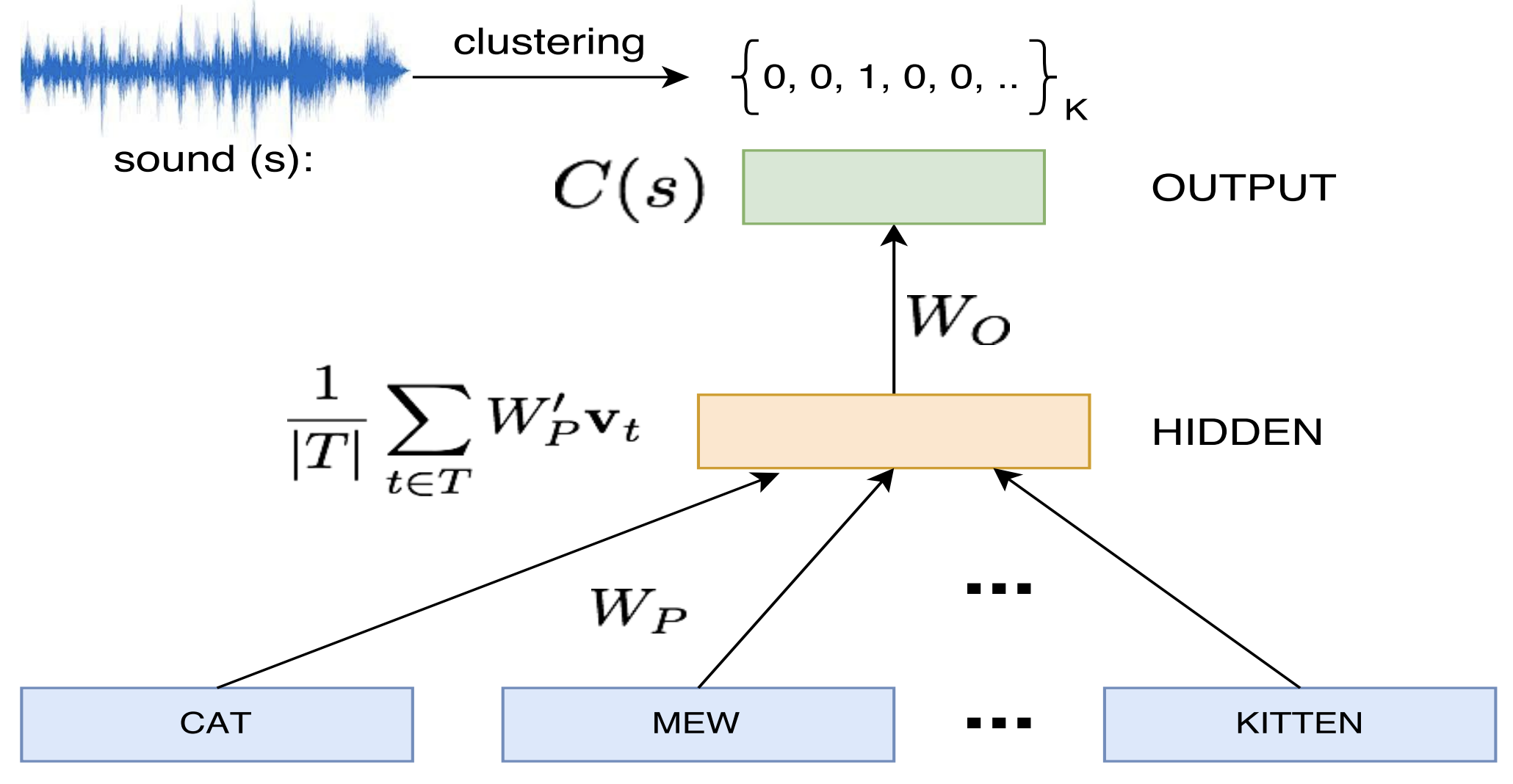 Sound-Word2Vec: Learning Word Representations Grounded in SoundsAshwin K Vijayakumar, Ramakrishna Vedantam, and Devi ParikhIn EMNLP, Mar 2017
Sound-Word2Vec: Learning Word Representations Grounded in SoundsAshwin K Vijayakumar, Ramakrishna Vedantam, and Devi ParikhIn EMNLP, Mar 2017To be able to interact better with humans, it is crucial for machines to understand sound - a primary modality of human perception. Previous works have used sound to learn embeddings for improved generic textual similarity assessment. In this work, we treat sound as a first-class citizen, studying downstream textual tasks which require aural grounding. To this end, we propose sound-word2vec - a new embedding scheme that learns specialized word embeddings grounded in sounds. For example, we learn that two seemingly (semantically) unrelated concepts, like leaves and paper are similar due to the similar rustling sounds they make. Our embeddings prove useful in textual tasks requiring aural reasoning like text-based sound retrieval and discovering foley sound effects (used in movies). Moreover, our embedding space captures interesting dependencies between words and onomatopoeia and outperforms prior work on aurally-relevant word relatedness datasets such as AMEN and ASLex.
-
 Counting Everyday Objects in Everyday ScenesPrithvijit Chattopadhyay, Ramakrishna Vedantam, Ramprasaath R Selvaraju, and 2 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Mar 2017
Counting Everyday Objects in Everyday ScenesPrithvijit Chattopadhyay, Ramakrishna Vedantam, Ramprasaath R Selvaraju, and 2 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Mar 2017We are interested in counting the number of instances of object classes in natural, everyday images. Previous counting approaches tackle the problem in restricted domains such as counting pedestrians in surveillance videos. Counts can also be estimated from outputs of other vision tasks like object detection. In this work, we build dedicated models for counting designed to tackle the large variance in counts, appearances, and scales of objects found in natural scenes. Our approach is inspired by the phenomenon of subitizing - the ability of humans to make quick assessments of counts given a perceptual signal, for small count values. Given a natural scene, we employ a divide and conquer strategy while incorporating context across the scene to adapt the subitizing idea to counting. Our approach offers consistent improvements over numerous baseline approaches for counting on the PASCAL VOC 2007 and COCO datasets. Subsequently, we study how counting can be used to improve object detection. We then show a proof of concept application of our counting methods to the task of Visual Question Answering, by studying the ‘how many?’ questions in the VQA and COCO-QA datasets.




2016
-
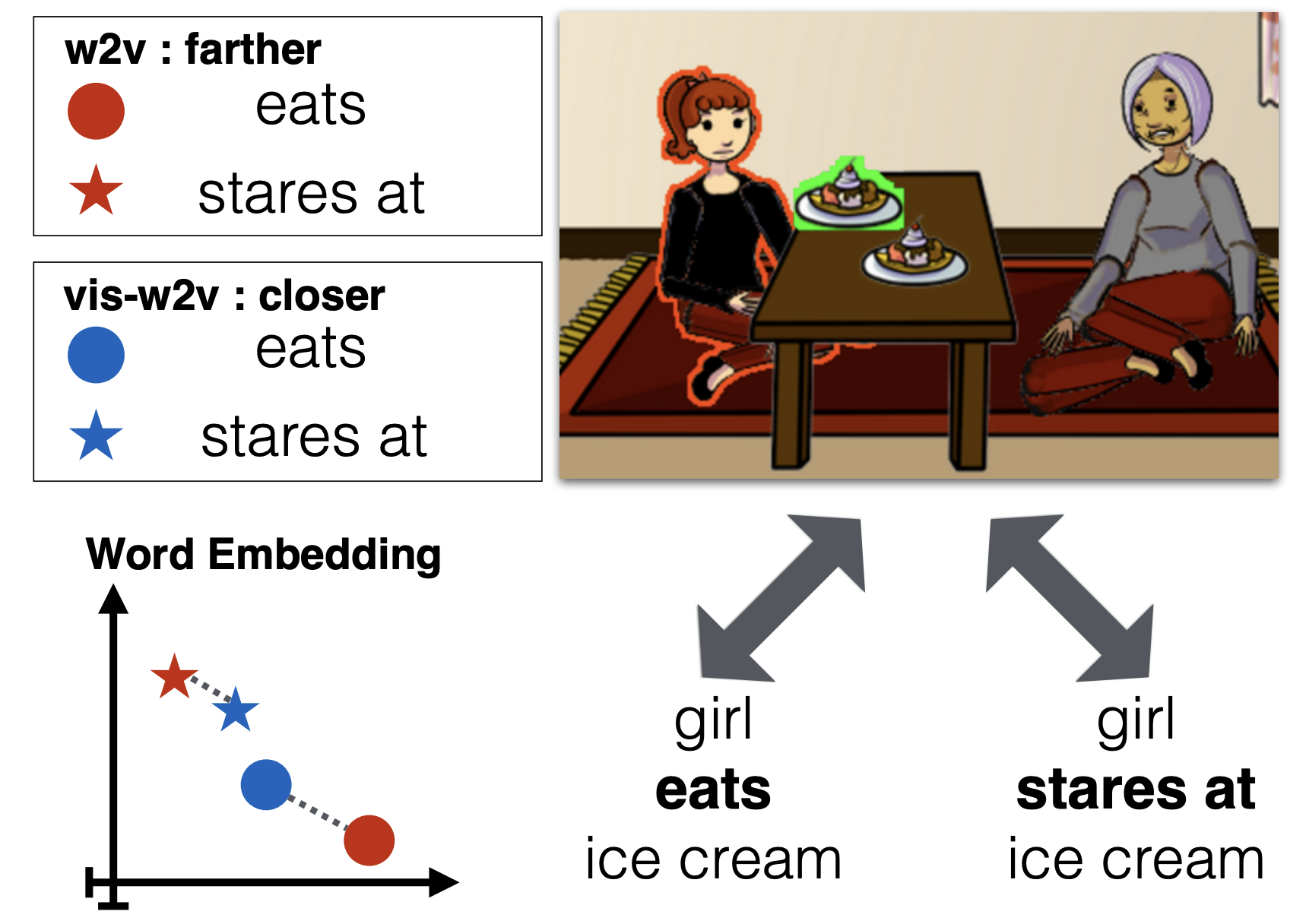 Visual word2vec (vis-w2v): Learning visually grounded word embeddings using abstract scenesS Kottur, R Vedantam, J M F Moura, and 1 more authorIn CVPR, Mar 2016
Visual word2vec (vis-w2v): Learning visually grounded word embeddings using abstract scenesS Kottur, R Vedantam, J M F Moura, and 1 more authorIn CVPR, Mar 2016We propose a model to learn visually grounded word embeddings (vis-w2v) to capture visual notions of semantic relatedness. While word embeddings trained using text have been extremely successful, they cannot uncover notions of semantic relatedness implicit in our visual world. For instance, although “eats” and “stares at” seem unrelated in text, they share semantics visually. When people are eating something, they also tend to stare at the food. Grounding diverse relations like “eats” and “stares at” into vision remains challenging, despite recent progress in vision. We note that the visual grounding of words depends on semantics, and not the literal pixels. We thus use abstract scenes created from clipart to provide the visual grounding. We find that the embeddings we learn capture fine-grained, visually grounded notions of semantic relatedness. We show improvements over text-only word embeddings (word2vec) on three tasks: common-sense assertion classification, visual paraphrasing and text-based image retrieval. Our code and datasets are available online.
-
 Adopting Abstract Images for Semantic Scene UnderstandingC Lawrence Zitnick, Ramakrishna Vedantam, and Devi ParikhIEEE TPAMI, Apr 2016
Adopting Abstract Images for Semantic Scene UnderstandingC Lawrence Zitnick, Ramakrishna Vedantam, and Devi ParikhIEEE TPAMI, Apr 2016Relating visual information to its linguistic semantic meaning remains an open and challenging area of research. The semantic meaning of images depends on the presence of objects, their attributes and their relations to other objects. But precisely characterizing this dependence requires extracting complex visual information from an image, which is in general a difficult and yet unsolved problem. In this paper, we propose studying semantic information in abstract images created from collections of clip art. Abstract images provide several advantages over real images. They allow for the direct study of how to infer high-level semantic information, since they remove the reliance on noisy low-level object, attribute and relation detectors, or the tedious hand-labeling of real images. Importantly, abstract images also allow the ability to generate sets of semantically similar scenes. Finding analogous sets of real images that are semantically similar would be nearly impossible. We create 1,002 sets of 10 semantically similar abstract images with corresponding written descriptions. We thoroughly analyze this dataset to discover semantically important features, the relations of words to visual features and methods for measuring semantic similarity. Finally, we study the relation between the saliency and memorability of objects and their semantic importance.


2015
-
 Learning common sense through visual abstractionRamakrishna Vedantam, Xiao Lin, Tanmay Batra, and 2 more authorsIn ICCV, Apr 2015
Learning common sense through visual abstractionRamakrishna Vedantam, Xiao Lin, Tanmay Batra, and 2 more authorsIn ICCV, Apr 2015Common sense is essential for building intelligent machines. While some commonsense knowledge is explicitly stated in human-generated text and can be learnt by mining the web, much of it is unwritten. It is often unnecessary and even unnatural to write about commonsense facts. While unwritten, this commonsense knowledge is not unseen! The visual world around us is full of structure modeled by commonsense knowledge. Can machines learn common sense simply by observing our visual world? Unfortunately, this requires automatic and accurate detection of objects, their attributes, poses, and interactions between objects, which remain challenging problems. Our key insight is that while visual common sense is depicted in visual content, it is the semantic features that are relevant and not low-level pixel information. In other words, photorealism is not necessary to learn common sense. We explore the use of humangenerated abstract scenes made from clipart for learning common sense. In particular, we reason about the plausibility of an interaction or relation between a pair of nouns by measuring the similarity of the relation and nouns with other relations and nouns we have seen in abstract scenes. We show that the commonsense knowledge we learn is complementary to what can be learnt from sources of text.
-
 CIDEr: Consensus-based Image Description EvaluationRamakrishna Vedantam, C Lawrence Zitnick, and Devi ParikhIn CVPR, Apr 2015
CIDEr: Consensus-based Image Description EvaluationRamakrishna Vedantam, C Lawrence Zitnick, and Devi ParikhIn CVPR, Apr 2015Automatically describing an image with a sentence is a long-standing challenge in computer vision and natural language processing. Due to recent progress in object detection, attribute classification, action recognition, etc., there is renewed interest in this area. However, evaluating the quality of descriptions has proven to be challenging. We propose a novel paradigm for evaluating image descriptions that uses human consensus. This paradigm consists of three main parts: a new triplet-based method of collecting human annotations to measure consensus, a new automated metric (CIDEr) that captures consensus, and two new datasets: PASCAL-50S and ABSTRACT-50S that contain 50 sentences describing each image. Our simple metric captures human judgment of consensus better than existing metrics across sentences generated by various sources. We also evaluate five state-of-the-art image description approaches using this new protocol and provide a benchmark for future comparisons. A version of CIDEr named CIDEr-D is available as a part of MS COCO evaluation server to enable systematic evaluation and benchmarking.

